AI-powered content pipeline for affiliate publishing
Solo Developer & ArchitectOverview
I designed and built DeskCurator end-to-end — an autonomous content pipeline that researches, writes, SEO-optimizes, and publishes affiliate articles for desk and work-from-home products. The system runs with minimal human intervention, using a Discord-based approval workflow as the single point of editorial control before anything goes live.
A topic goes in, and the pipeline orchestrates multiple AI agents to research products via web search, generate long-form articles in three distinct formats, optimize for search engines with structured data for rich snippets, publish to WordPress as drafts, and schedule social distribution across platforms over a 10-day cadence.
The Pipeline in Action
From research to publishing to social distribution — three snapshots showing a single article moving through the pipeline.
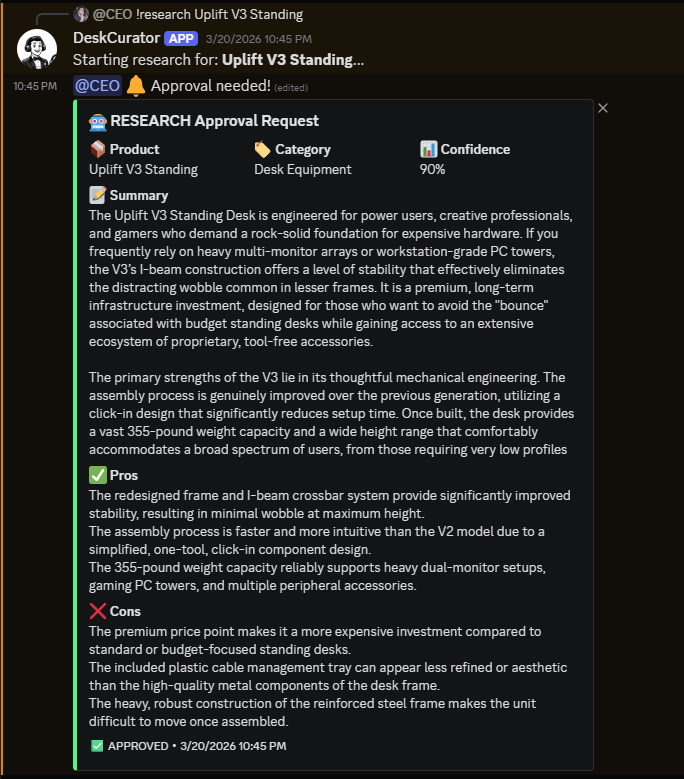
AI research & approval via Discord
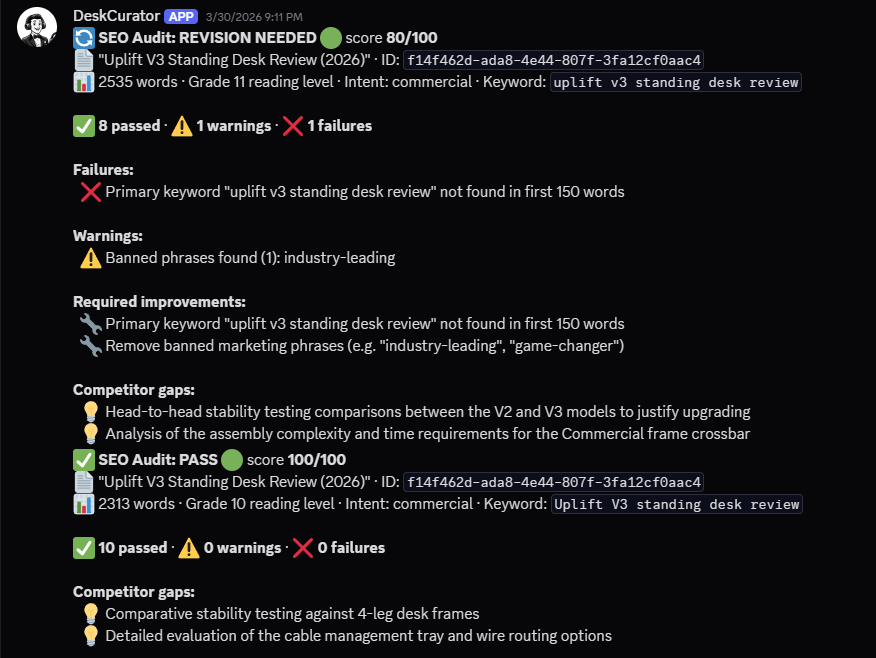
SEO audit: 80 → 100 after optimization
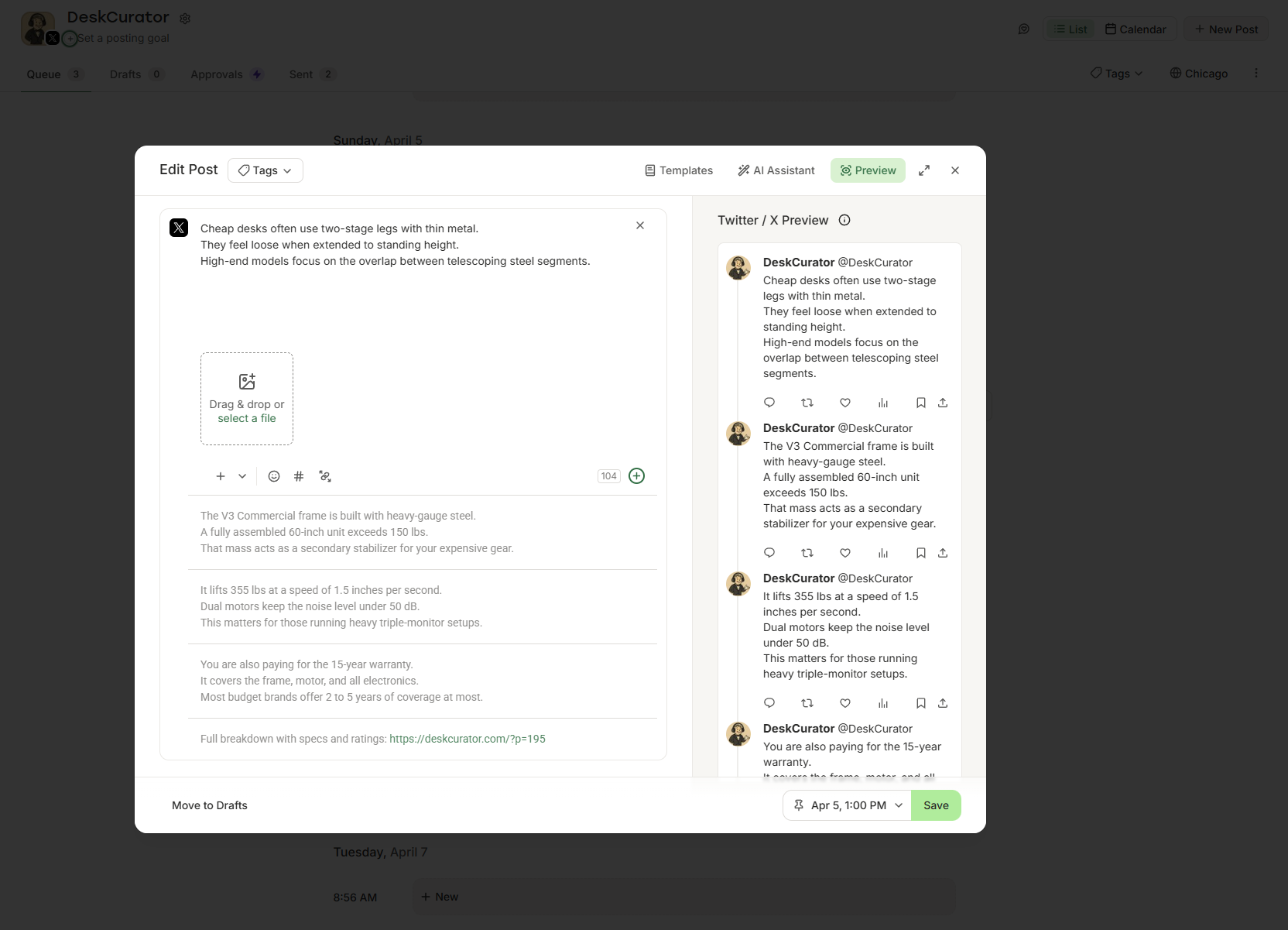
Auto-generated threads via Buffer
Architecture
The system is a multi-agent TypeScript architecture running in Docker, deployed via a CI/CD pipeline on a self-hosted GitHub Actions runner. A hybrid sync/async processing model keeps things fast where it matters — synchronous calls for classification and routing, with an async SQLite-backed job queue for parallelized research across multiple products.
ContentResearcher
Web search and product data aggregation with ChromaDB vector deduplication to prevent repeated coverage.
ContentWriter
Three specialized generation prompts — roundups, setup guides with tiered recommendations, and single-product reviews.
SEOOptimizer
Metadata, internal linking suggestions, and structured data markup for rich snippet eligibility.
SocialAgent
Converts articles into platform-native threads and posts, scheduling distribution via Buffer over 10 days.
Key Technical Decisions
Draft-first publishing was a deliberate choice — every article lands as a WordPress draft with a Discord notification for human review before going live. This preserves editorial quality without slowing down the pipeline’s throughput.
Building for resumability early on (queue-based processing, idempotent jobs) paid off significantly. When a research step fails mid-run, the system picks up where it left off rather than restarting from scratch. The architecture also supports multi-provider switching for the AI layer, so swapping or A/B testing models doesn’t require reworking the agents.
What I Learned
Specialized prompts per content type dramatically outperform a single generic generation prompt. Three tailored prompts produce better results than one flexible one trying to cover every format.
Human-in-the-loop doesn’t have to mean human-in-the-way. A lightweight Discord approval step gives editorial control without becoming a bottleneck in the pipeline.
Environment separation discipline matters early. Keeping local dev, CI, and production configs strictly isolated prevented an entire category of “works on my machine” deployment bugs.