WorkBuddy
AI-powered workplace leadership coaching platform
Solo Developer & ArchitectOverview
WorkBuddy is a full-stack AI coaching platform I designed and built end-to-end. Users define real workplace challenges — improving team morale, navigating a difficult conversation, building a leadership habit — and receive ongoing, contextual guidance from an AI coach named Simon. Simon isn’t a chatbot that answers questions. He’s an opinionated coaching agent grounded in purpose-driven leadership principles, capable of both empathetic conversational coaching and structured analytical insights.
The platform lets users create challenges with defined timelines, success criteria, and measurable metrics, then tracks progress while Simon provides coaching that adapts to the user’s specific context and conversation history.
Platform in Action
From challenge creation to AI coaching to progress tracking — three views of the platform experience.
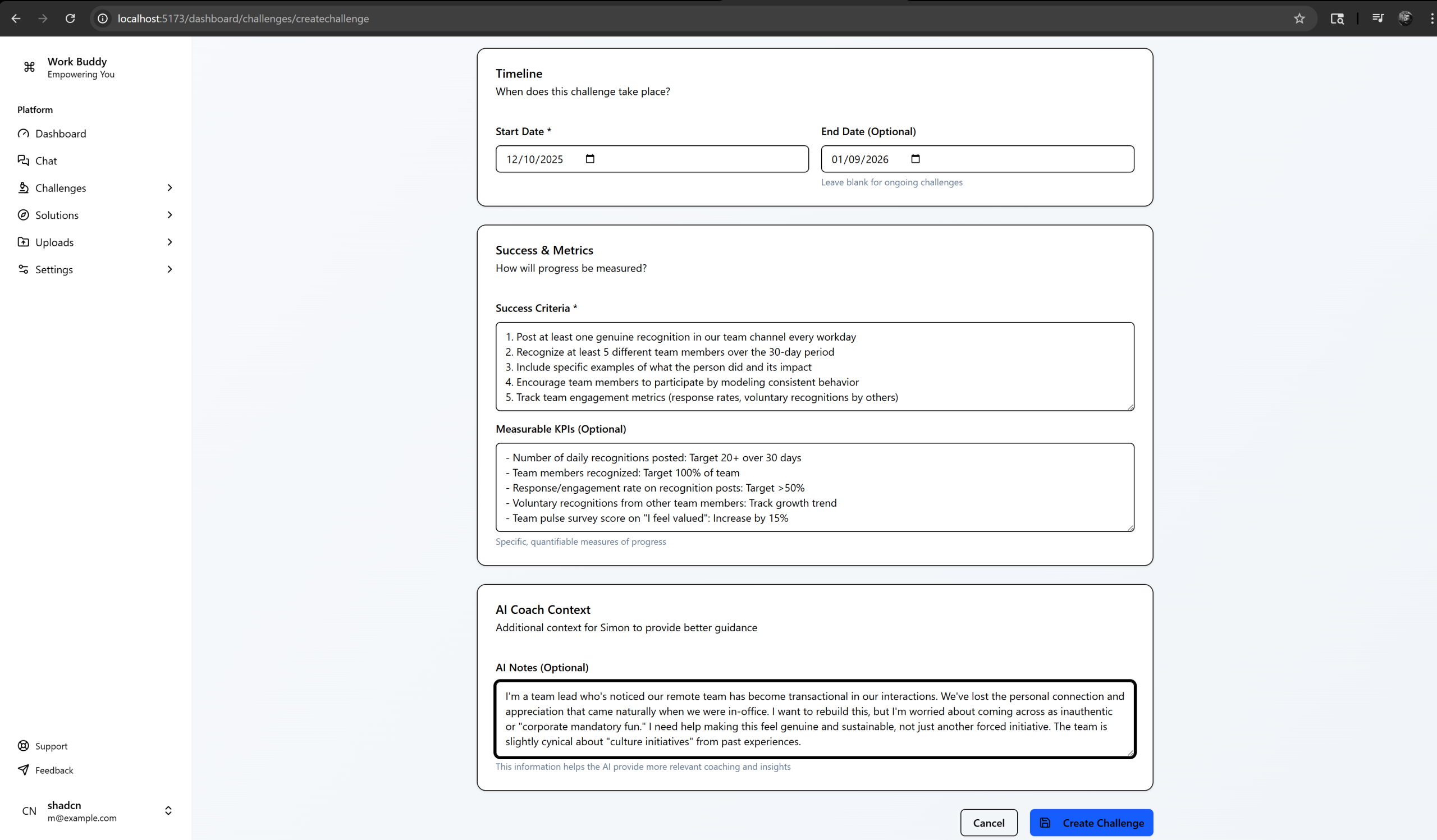
Structured challenge definition
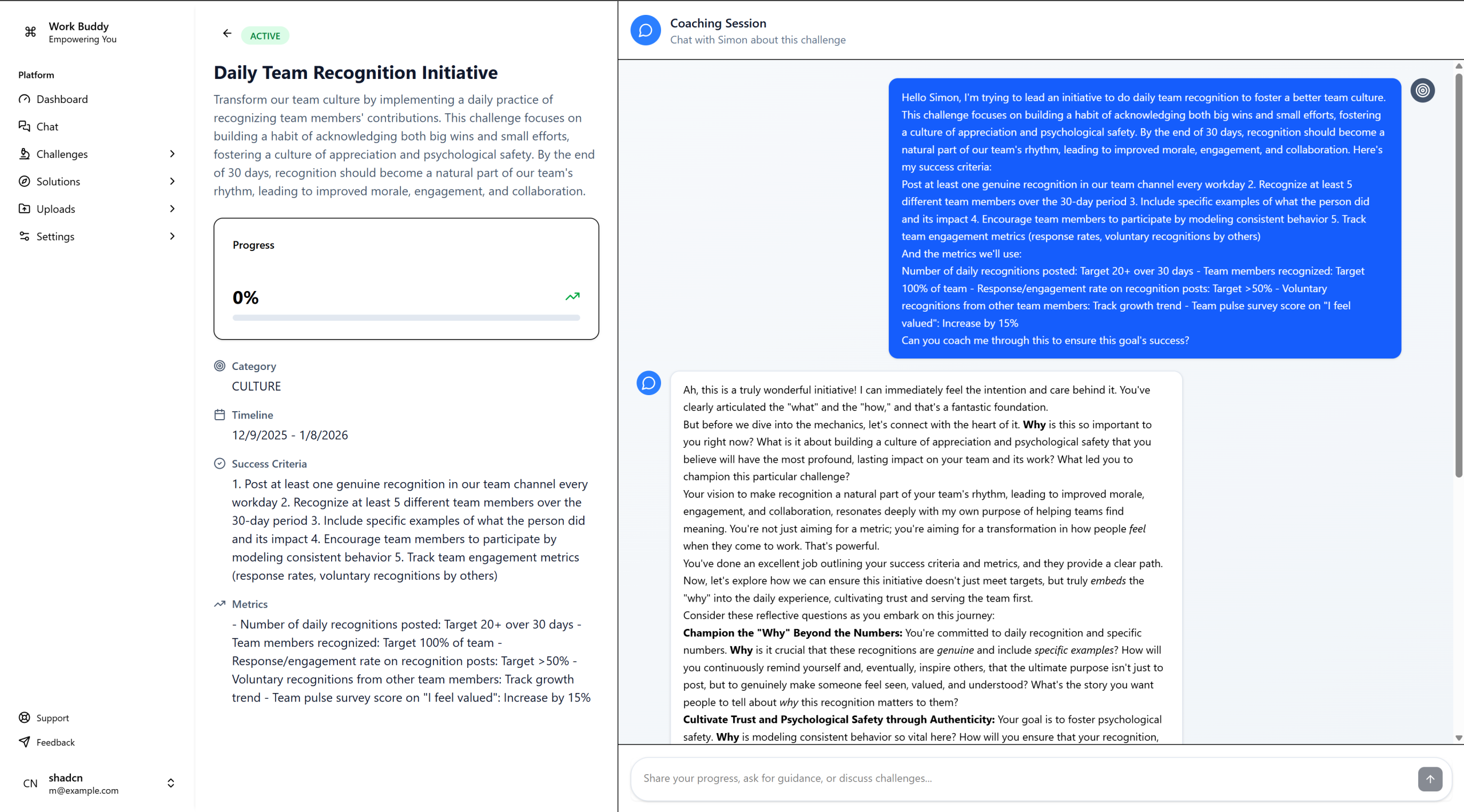
Contextual AI coaching with Simon
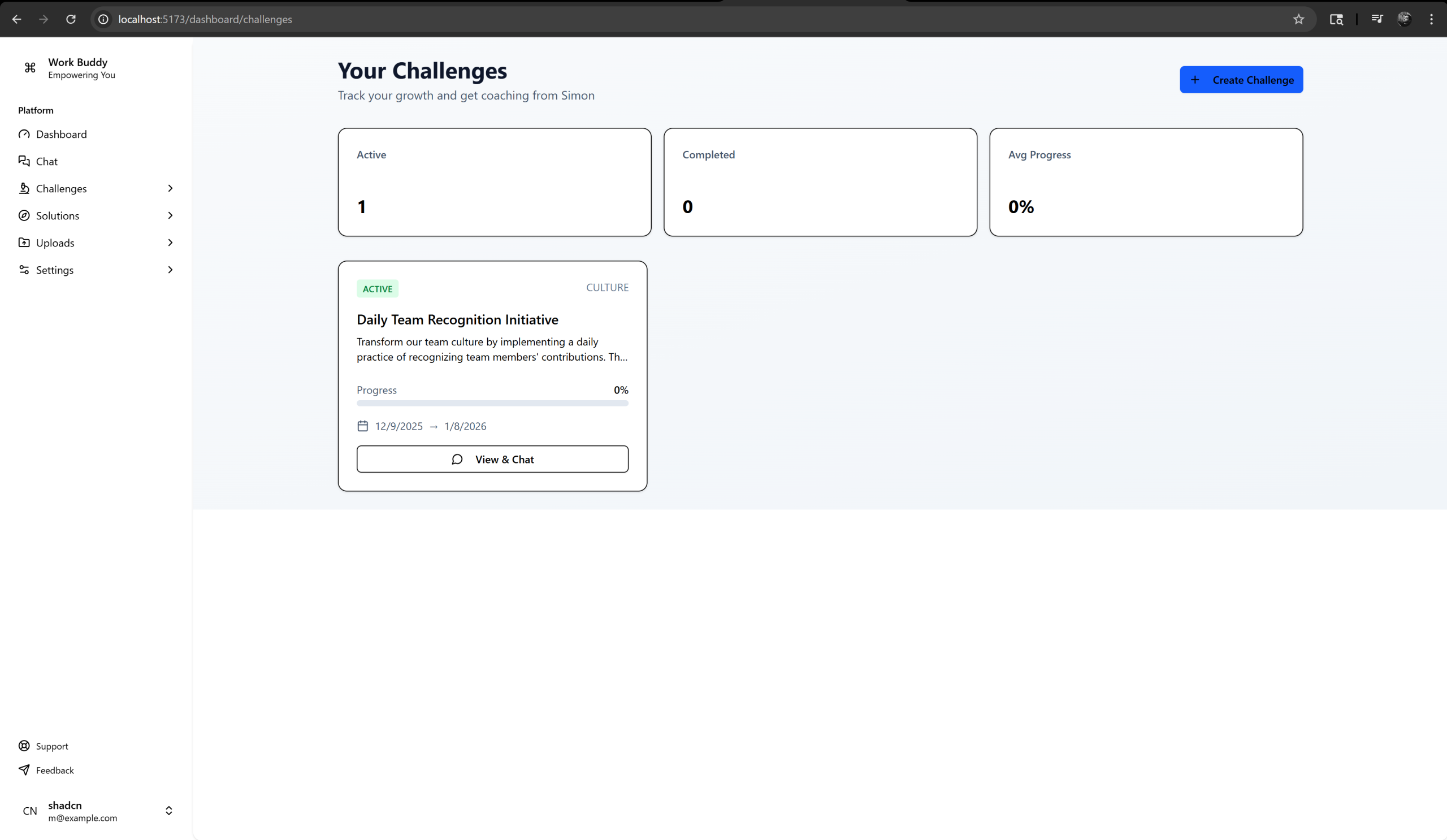
Progress breakdown & tracking
Architecture
A 3-tier architecture separates the React frontend, Express API backend, and a dedicated AI agent service — keeping LLM integration decoupled from core business logic so the coaching layer can evolve independently. ChromaDB powers the RAG pipeline with separate collections tuned for conversations, insights, and the leadership knowledge base.
AI Agent Service
Decoupled coaching layer with dual response modes — conversational empathetic coaching and structured JSON analytical insights — as distinct prompt paths, not just tone adjustments.
RAG Pipeline
ChromaDB vector store with cosine-similarity retrieval across three collections. Leadership frameworks and domain knowledge retrieved semantically at inference time.
Express API
RESTful backend with Prisma ORM managing challenges, conversations, progress tracking, and user state in PostgreSQL.
React Frontend
TypeScript React app with dynamic navigation, challenge management, real-time chat, and interactive progress breakdowns.
Engineering Deep-Dive
Diagnosing RAG Poisoning in Production
Mid-development, Simon’s responses became increasingly verbose and philosophical — every reply opened with sweeping motivational statements regardless of what was asked. I traced the root cause to a subtle architectural issue: personality and tone documents (voice guidelines, behavioural commitments, coaching principles) had been ingested into ChromaDB alongside the knowledge base. Semantic search was retrieving these as “relevant context” and injecting them into the prompt on top of the system prompt that already contained the same instructions — creating a compounding feedback loop.
The fix required enforcing a clear boundary between “who the agent is” (system prompt layer only) and “what the agent knows” (vector store). I restructured the ingestion pipeline to exclude personality documents from ChromaDB, added a category-based safety filter in the retrieval service, and rewrote the prompt chain with direct language that the LLM couldn’t over-interpret.
What I Learned
RAG systems can silently degrade when the boundary between agent identity and retrievable knowledge isn’t enforced at the data layer. Personality documents belong in the system prompt, never in the vector store.
Prompt language interacts with retrieval systems in non-obvious ways. Instructions like “always start with why” get interpreted literally by LLMs, producing unintended stylistic patterns that compound with each retrieval cycle.
Simpler data structures win at the LLM layer. A flat challenge model avoids the context mixing and hallucination issues that complex parent-child hierarchies introduce when feeding data to language models.